Cos’è il web scraping e a cosa serve
Sicuramente ti sarai chiesto cosa sia il web scraping. Si tratta di un processo che utilizza i bots per estrarre contenuto e dati di un sito web. Si estrae il codice HTML. E con lui i dati immagazzinati nel database. Ciò suppone che si possa duplicare o copiare tutto il contenuto di un sito web.
Il web scraping si utilizza in molte aziende digitali che si dedicano alla raccolta di database. Per chiarire meglio cosa sia il web scraping devi sapere quali sono i casi di uso legittimo:
- I robots dei motori di ricerca verificano un sito, analizzano il contenuto e poi lo classificano.
- Siti di comparazione di prezzi che implementano bots per ottenere automaticamente prezzi e descrizioni di prodotti per siti web partners.
- Aziende di analisi di mercato che utilizzano questo sistema per estrarre dati da forum e social.
Per ottenere più informazioni riguardo a cosa sia il web scraping devi sapere che si utilizza anche per fini illegali. Incluso il furto di contenuto con diritti di autore. Un’entità digitale colpita può patire gravi perdite finanziarie, specialmente se si tratta di un’attività che si basa su modelli di prezzi competitivi o offerte nella distribuzione di contenuto.
Sai davvero cosa sia il web scraping?
Gli strumenti di web scraping sono software, ossia bots programmati per esaminare database e estrarre informazioni. Si utilizzano diversi bot, molti dei quali personalizzabili, per:
- Riconoscere strutture di siti HTML unici
- Estrarre e trasformare contenuti
- Immagazzinare dati
- Estrarre dati tramite API
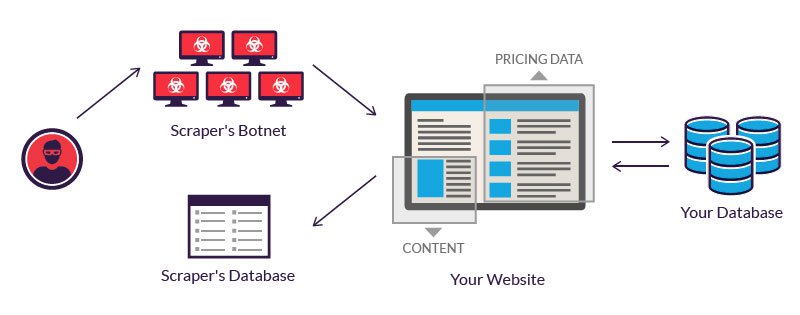
Dato che tutti i bots utilizzano lo stesso sistema per accedere ai dati del sito a volte può essere difficile distinguere tra bots legittimi e bots truffaldini.
Differenze chiave tra bots legittimi e truffaldini
- I bots legittimi si identificano con l’organizzazione per cui lavorano. Per esempio, Googlebot si identifica per il suo header http come appartenente a Google. I robots truffaldini, invece, si spacciano per traffico legittimo, utilizzando un utente http falso.
- I robots legittimi rispettano il file robot.txt di un sito, che raccoglie pagine a cui può o non può accedere un robot. I robot truffaldini invece verificano tutto il sito indipendentemente dal fatto di avere il permesso.
Gli operatori leggittimi di bots investono nei server per processare una grande quantità di dati estratti. Un hacker spesso ricorre a una rete di bots con server ubicati in luoghi sconosciuti e infettati con un malware.
Il potere combinato dei sistemi infette permette di danneggiare diversi siti.
Esempi di web scraping

Il web scraping si considera dannoso quando i dati si estraggono senza permesso dei proprietari dei siti. I due casi di utilizzo più comune sono il furto di prezzi e contenuto.
1 – Furto di prezzi
Il furto di prezzi è una delle varianti per sapere cosa sia il web scraping. Si tratta di un attacco che utilizza i bots tramite i quali lancia bots di web scraping per ispezionare i database della concorrenza. L’obiettivo è accedere alle informazioni di prezzo e rubare clienti alla concorrenza. Un furto di prezzi che ha successo può rendere le offerte migliori su un sito di comparazione prezzi.
Gli attacchi sono frequenti nei settori dove i prezzi dei prodotti sono facilmente comparabili. Perché il prezzo ha un ruolo importante nelle decisioni di acquisto. Le vittime del furto di prezzi possono essere agenzie di viaggi, chi commercia in elettronica, ecc.
Per esempio chi commercia in telefonini e vende prodotti con prezzi importanti, è una facile preda. Per essere competitivi devono vendere i loro prodotti al miglior prezzo possibile.
Dato che i clienti scelgono sempre l’offerta più economica, per ottenere un vantaggio, un fornitore può usare un bot per verificare i siti della concorrenza e aggiornare istantaneamente i suoi prezzi.
2 – Furto di contenuto
Il furto di contenuto è un altro aspetto che permette di capire cosa sia il web scraping. Ossia, il furto di contenuto su larga scala in un sito determinato. Gli obiettivi tipici includono cataloghi prodotti e siti che si basano su contenuto digitale per spingere l’attività. Per queste aziende un furto di contenuto può essere devastante.
Per esempio le directories online investono molto tempo, denaro e energia nel costruire i propri database. Il furto può rovinare tutto. Si usa nelle campagne di posta indesiderata. O si rivende ai competitors. È probabile che tutto ciò influisca sui risultati aziendali.
Protezione contro il web scraping
1 – Bisogna agire in maniera legale
Il modo più facile per evitare il furto è prendere misure legali. Una è quella di denunciare l’attacco dimostrando il furto.
Poi anche contattare chi si è impossessato dei tuoi dati se esplicitamente hai segnalato che non si tratta di contenuti pubblici. Per esempio LInkedin ha contattato una serie utenti segnalando che l’estrazione dei dati attraverso richieste automatizzate equivale a pirateria.
2 – Prevenire attacchi tra le richieste in arrivo
Anche se hai pubblicato un avviso legale che proibisce l’impossessamento dei tuoi dati, è possibile che qualcuno continui a farlo. Puoi identificare gli indirizzi IP e evitare che le richieste arrivino al tuo servizio utilizzando un firewall.
Anche se è un processo manuale, i provider moderni di servizi cloud ti danno accesso a strumenti che bloccano possibili attacchi. Per esempio se hai un hosting dei tuoi servizi su Amazon, lo scudo AWS ti aiuta a proteggere il tuo server da possibili attacchi.
3 – Usare tokens di falsificazione richieste (CSRF)
Usando tokens CSRF nella tua applicazione eviterai che gli strumenti automatizzati effettuino richieste arbitrarie all’URL degli invitati. Un token CSRF può essere presente come un campo di un form occulto.
Per rilevare un token CSRF devi analizzare il mercato e cercare il token corretto prima di inserirlo nella richiesta. Questo processo richiede abilità di programmazione e l’accesso a strumenti professionali.
4 – Usa il file .htaccess per evitare il furto
.htaccess è un file di configurazione per il tuo server web. E si può modificare per evitare che i tuoi dati vengano estratti. Il primo passo è identificare chi vuole accedere ai tuoi dati tramite Google Webmasters.
Una volta che hai identificato questi utenti puoi usare diverse tecniche per ridurre l’estrazione, cambiando il file di configurazione. In generale questo file non è abilitato quindi devi farlo, solo così i file che inserirai nella directory saranno accettati.
5 – Prevenire l’hotlinking
Quando il tuo contenuto viene estratto, i link online e le immagini e altri files vengono copiati direttamente sul sito di chi effettua l’attacco. Quando si mostra lo stesso contenuto nel sito di chi ha effettuato l’attacco, questa risorsa si lega direttamente al tuo sito.
Il processo di mostrare contenuto ubicato nel server di un sito diverso si chiama hotlinking. Ciò che viene mostrato non deriva direttamente dal tuo server.
6 – Indirizzi IP specifici in black list
Se hai identificato gli indirizzi IP o i modelli di indirizzi IP che si usano per estrarre contenuti, puoi bloccarli attraverso il tuo .htaccess.
7 – Limita il numero di richieste di un indirizzo IP
Come alternativa, puoi anche limitare il numero di richieste di un indirizzo IP. Anche può non essere utile se un attacco viene effettuato attraverso diversi indirizzi IP. Puoi anche usare un captcha nel caso di richieste anomale di un indirizzo IP.
Ciò che devi fare è bloccare l’accesso dagli indirizzi IP CONOSCIUTI per assicurarti che un attacco non possa sfruttare la richiesta per copiare o eliminare i tuoi dati.
8 – Creare ‘honeypots’
Un ‘honeypot’ è un link a contenuto falso che è invisibile agli utenti ma è presente nell’HTML. Compare quando un programma analizza il sito web. Inviando il ladro di contenuti verso gli honeypots, puoi rilevare chi sono e inviarli a pagine prive di contenuto.
Quindi, non dimentiarti di disabilitare questi link dal tuo file robots.txt per assicurarti che non ci siano links a honeypots rilevati dai motori di ricerca.
9 – Cambiare la struttura dell’HTML con frequesnza
La maggior parte degli estrattori di contenuti analizza l’HTML che si ottiene dal server. Per rendere difficoltoso l’accesso ai dati puoi cambiare la struttura dell’HTML. Per farlo, un hacker dovrà valutare nuovamente la struttura del tuo sito per estrarre i dati. Un’altra chiave per comprendere meglio il web scraping.
10 – Offrire APIs
Puoi permettere l’estrazione selettiva dei dati dal tuo sito se stabilisci alcune regole. Un modo è creare APIs basate sull’iscrizione per monitorare e dare accesso ai tuoi dati. Attraverso le APIs puoi anche supervisionare e restringere l’uso del servizio che offri.
Se non vuoi avere problemi di web scraping o complicazioni di alcun tipo devi sempre fidarti di piattaforme che offrano sicurezza. E che ti offrano i servizi necessari per ogni campagna di marketing. In Antevenio possiamo aiutarti in questo senso. Fidati dei nostri servizi di Influencer e Content Marketing e vedrai come saranno facili da usare e efficaci.
