
Seguro que alguna vez te has preguntado qué es el web scraping. Se trata de un proceso de usar bots para extraer contenido y datos de un sitio web. De esta forma se extrae el código HTML. Y, con él, los datos almacenados en la base de datos. Esto supone que se puede duplicar o copiar todo el contenido del sitio web en otro lugar.
El web scraping se utiliza en muchas empresas digitales que se dedican a la recopilación de bases de datos. Para aclarar mejor qué es el web scraping debes saber cuáles son los casos de uso legítimo del mismo:
- Los robots de los motores de búsqueda rastrean un sitio, analizan su contenido y luego lo clasifican.
- Sitios de comparación de precios que implementan bots para obtener automáticamente precios y descripciones de productos para sitios web de vendedores aliados.
- Compañías de investigación de mercado que lo utilizan para extraer datos de foros y redes sociales.
Para tener más información sobre qué es el web scraping debes saber que también se utiliza para fines ilegales. Incluida el raspado de precios y el robo de contenido con derechos de autor. Una entidad digital afectada puede sufrir graves pérdidas financieras. Especialmente si se trata de un negocio que se basa fundamentalmente en modelos de precios competitivos u ofertas en la distribución de contenido.
¿Sabes realmente qué es el web scraping?
Las herramientas de web scraping son software, es decir, bots programados para examinar bases de datos y extraer información. Se utiliza una gran variedad de tipos de bot, muchos de ellos totalmente personalizables para:
- Reconocer estructuras de sitios HTML únicos.
- Extraer y transformar contenidos.
- Almacenar datos.
- Extraer datos de las API.
Dado que todos los bots utilizan el mismo sistema para acceder a los datos del sitio, a veces puede resultar difícil distinguir entre bots legítimos y bots maliciosos.
Diferencias clave entre bots legítimos y maliciosos
Existen algunas diferencias clave que te ayudarán a distinguir entre los dos:
- Los robots legítimos se identifican con la organización para la que lo hacen. Por ejemplo, Googlebot se identifica en su encabezado HTTP como perteneciente a Google. Los robots maliciosos, a la inversa, se hacen pasar por tráfico legítimo al crear un usuario HTTP falso.
- Los robots legítimos respetan el archivo robot.txt de un sitio, que enumera las páginas a las que puede acceder un robot y las que no. Los maliciosos, por otro lado, rastrean el sitio web independientemente de lo que el operador del sitio haya permitido.
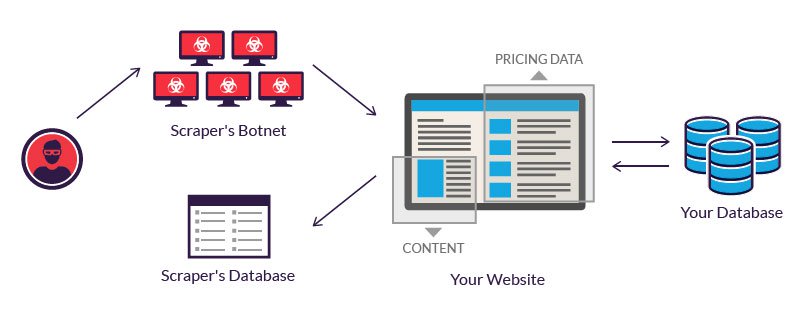
Los operadores legítimos de bots invierten en servidores para procesar la gran cantidad de datos que se extraen. Un atacante, que carece de tal presupuesto, a menudo recurre al uso de una red de bots. Es decir, computadoras geográficamente dispersos, infectadas con el mismo malware y controladas desde una ubicación central.
Los propietarios de ordenadores de bots individuales desconocen su participación. El poder combinado de los sistemas infectados permite el raspado a gran escala de muchos sitios web diferentes por parte del autor.
Ejemplos de qué es el web scraping

El web scraping se considera malicioso cuando los datos se extraen sin el permiso de los propietarios de sitios web. Los dos casos de uso más comunes son el raspado de precios y el robo de contenido.
1.- Raspado de precios
En el raspado de precios es una de las variantes para saber qué es el web scraping. Se trata de un atacante que generalmente utiliza una red de bots desde la cual lanzar bots de web scraping para inspeccionar las bases de datos de la competencia. El objetivo es acceder a la información de precios, ganar a los rivales e impulsar las ventas. Para los atacantes, un raspado de precios exitoso puede hacer que sus ofertas sean destacadas en sitios web de comparación.
Los ataques ocurren con frecuencia en industrias donde el precio de los productos son fácilmente comparables. Porque el precio juega un papel importante en las decisiones de compra. Las víctimas del raspado de precios pueden ser agencias de viajes, vendedores de electrónica en línea, etc.
Por ejemplo, los comerciantes electrónicos de teléfonos inteligentes, que venden productos similares a precios relativamente importantes, son objetivos frecuentes. Para seguir siendo competitivos, tienen que vender sus productos al mejor precio posible.
Ya que los clientes siempre suelen optar por la oferta más económica. Para obtener una ventaja, un proveedor puede usar un bot para raspar continuamente los sitios web de sus competidores y actualizar casi instantáneamente sus propios precios en consecuencia.
2.- Raspado de contenido
El raspado de contenido es otra de las formas que permite comprender qué es el web scraping. Es decir, el robo de contenido a gran escala de un sitio determinado. Los objetivos típicos incluyen catálogos de productos en línea y sitios web que se basan en contenido digital para impulsar el negocio. Para estas empresas, un ataque de raspado de contenido puede ser devastador.
Por ejemplo, los directorios de negocios en línea invierten cantidades significativas de tiempo, dinero y energía en la construcción de su base de datos. El raspado puede hacer que todo se vaya al traste. Se usa en campañas de envío de correo no deseado. O se revende a los competidores. Es probable que cualquiera de estos hechos afecte a los resultados de una empresa y a sus operaciones diarias.
Protección contra el web scraping
1.- Es importante actuar de forma legal
La forma más fácil de evitar el raspado es tomar una medida legal. Una en la que puedas denunciar judicialmente el ataque y en la que demuestres que el raspado web no está permitido.
Incluso puedes demandar a posibles raspadores si lo has prohibido explícitamente en tus términos de servicio. Por ejemplo, LinkedIn demandó a un conjunto de raspadores el año pasado, diciendo que la extracción de datos de usuarios a través de solicitudes automatizadas equivale a piratería.
2.- Prevenir ataques de las solicitudes que lleguen
Incluso si has publicado un aviso legal que prohíba el raspado de tus servicios, es posible que un atacante potencial aún quiera seguir adelante con el proceso. Puedes identificar posibles direcciones IP y evitar que las solicitudes lleguen a tu servicio filtrando a través del firewall.
Aunque es un proceso manual, los proveedores modernos de servicios en la nube te dan acceso a herramientas que bloquean posibles ataques. Por ejemplo, si estás alojando tus servicios en los servicios web de Amazon, el Escudo de AWS ayudaría a proteger tu servidor de posibles ataques.
3.- Usar tokens de falsificación de solicitud (CSRF)
Al usar tokens CSRF en tu aplicación, evitarás que las herramientas automatizadas realicen solicitudes arbitrarias a las URL de los invitados. Un token CSRF puede estar presente como un campo de formulario oculto.
Para sortear un token CSRF, es necesario cargar y analizar el marcado y buscar el token correcto, antes de agruparlo junto con la solicitud. Este proceso requiere habilidades de programación y el acceso a herramientas profesionales.
4.- Usa el archivo .htaccess para evitar el raspado
.htaccess es un archivo de configuración para tu servidor web. Y se puede modificar para evitar que los raspadores accedan a tus datos. El primer paso es identificar los raspadores, que se puede realizar a través de Google Webmasters.
Una vez que los hayas identificado, puedes usar muchas técnicas para detener el proceso de raspado cambiando el archivo de configuración. En general, este archivo no está habilitado por lo que debes estar habilitado, solamente así se interpretarán los archivos que tú colocarás en tu directorio.
5.- Prevenir hotlinking
Cuando se raspa tu contenido, los enlaces en línea a las imágenes y otros archivos se copian directamente en el sitio del atacante. Cuando se muestra el mismo contenido en el sitio del atacante, dicho recurso se vincula directamente a tu sitio web.
Este proceso de mostrar un recurso que está alojado en el servidor en un sitio web diferente se llama hotlinking. Cuando evitas un enlace activo, una imagen de este tipo, cuando se muestra en un sitio diferente, no se hace a través de tu servidor.
6.- Direcciones IP específicas de listas negras
Si has identificado las direcciones IP o los patrones de direcciones IP que se utilizan para raspar, simplemente puedes bloquearlas a través de tu .htaccess.
7.- Limita el número de solicitudes de una dirección IP
Como alternativa, también puedes limitar el número de solicitudes de una dirección IP. Aunque puede no ser útil si un atacante tiene acceso a varias direcciones IP. También se puede usar un captcha en caso de solicitudes anormales de una dirección IP.
Lo que tienes que hacer es bloquear el acceso desde las direcciones IP conocidas del servicio de alojamiento y rastreo en la nube para asegurarse de que un atacante no pueda usar dicho servicio para eliminar o copiar tus datos.
8.- Crear «honeypots«
Un «honeypot» es un enlace a contenido falso que es invisible para un usuario normal, pero está presente en el HTML. Aparecería cuando un programa analiza el sitio web. Al redirigir un raspador a dichos honeypots, puede detectar raspadores y hacer que desperdicien recursos al visitar páginas que no contienen datos.
Por tanto, no olvides deshabilitar esos enlaces en tu archivo robots.txt para asegurarte de que un buscador de motores de búsqueda no termine en tales honeypots.
9.- Cambiar la estructura del HTML con frecuencia
La mayoría de los rastreadores analizan el HTML que se obtiene del servidor. Para dificultar el acceso de los raspadores a los datos, puedes cambiar con frecuencia la estructura del HTML. Para hacerlo, un atacante deberá evaluar nuevamente la estructura de tu sitio web para extraer los datos. Otra de las claves para saber qué es el web scraping.
10.- Proporcionar APIs
Puedes permitir la extracción selectiva de datos de tu sitio si estableces ciertas reglas. Una forma es crear APIs basadas en suscripciones para monitorear y dar acceso a tus datos. A través de las APIs, también podrás supervisar y restringir el uso del servicio que ofreces.
Si no quieres tener problemas de web scraping ni complicaciones de ningún tipo siempre debes confiar en plataformas que te aporten la seguridad. Y que además, te ofrezcan los servicios que necesitas para cada campaña de marketing. Y en Antevenio te podemos ayudar en ese sentido. Confía en nuestros servicios de Branded & Content Marketing y verás cómo te resultará fácil y efectivo.